|
Selected Research
(For the most up-to-date publications, please visit my
Google Scholar
)
|
|
|
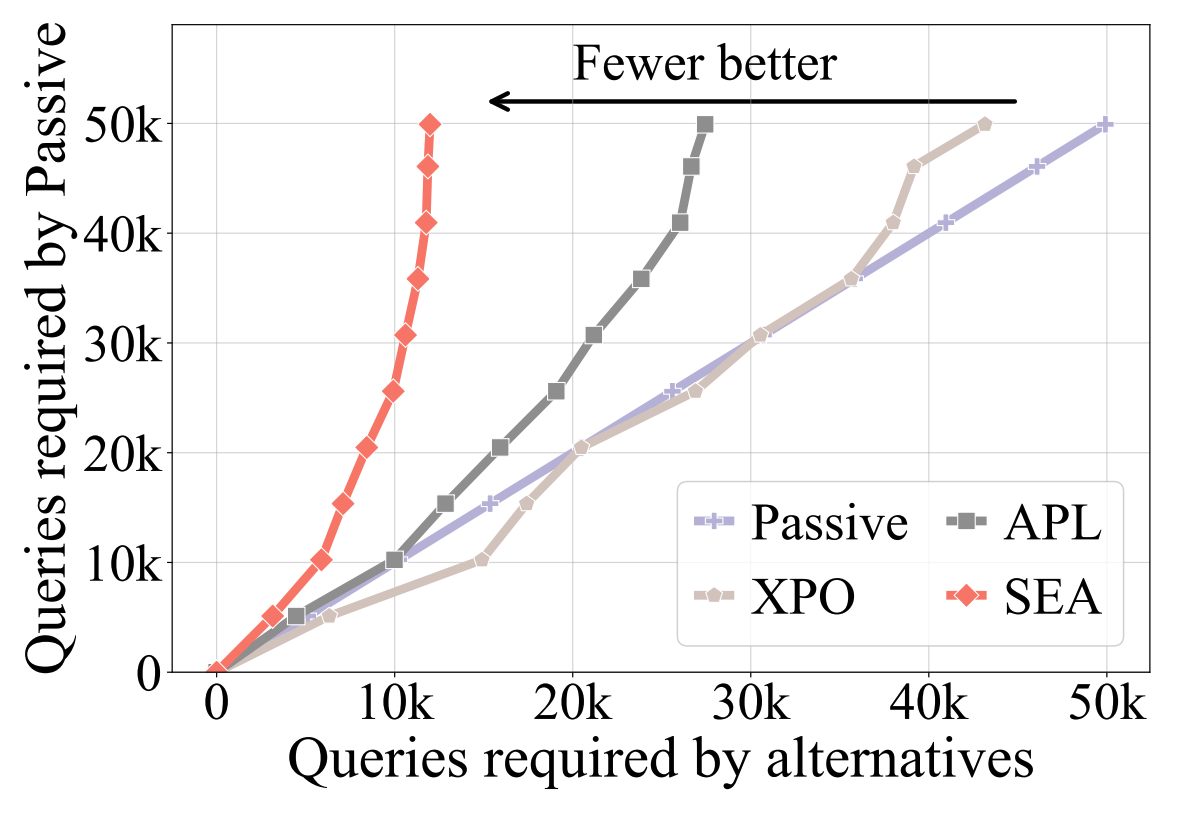
Sample-Efficient Alignment for LLMs
Zichen Liu,
Changyu Chen,
Chao Du†,
Wee Sun Lee,
Min Lin
LanGame @ Advances in Neural Information Processing Systems (LanGame @
NeurIPS), 2024
arXiv /
code
|
|
|
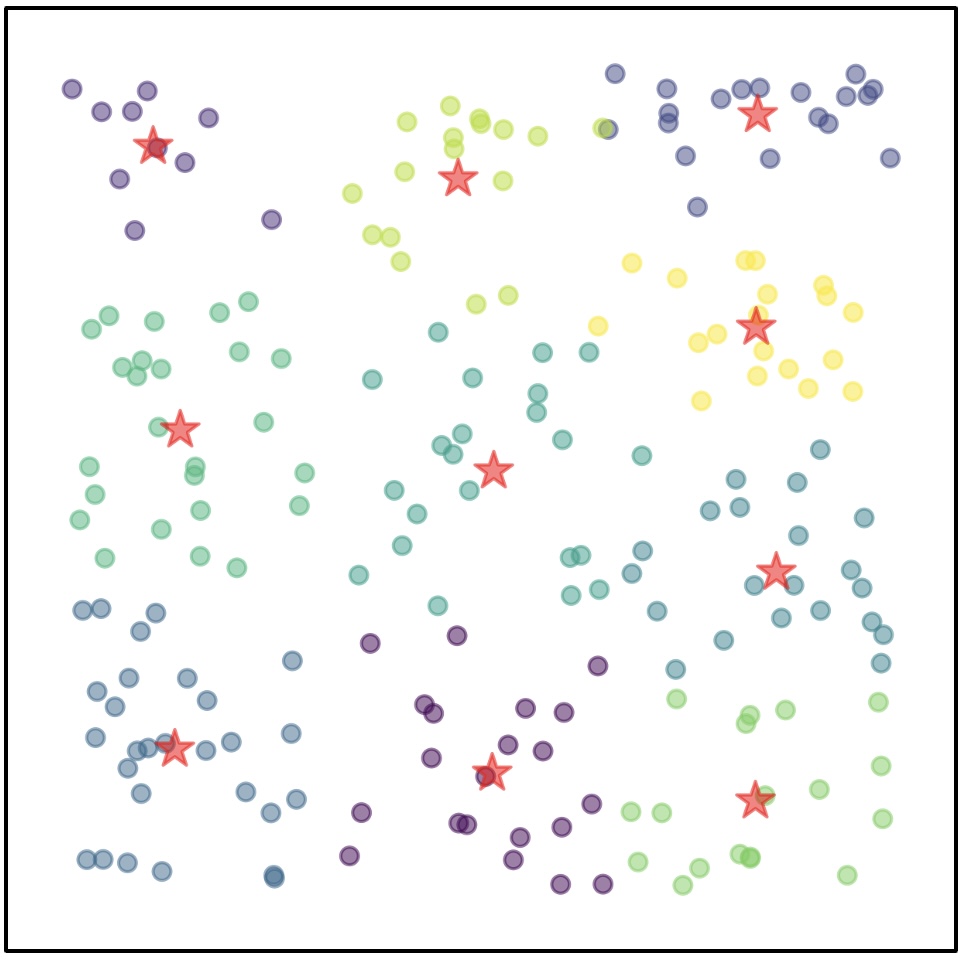
Bootstrapping Language Models with DPO Implicit Rewards
Changyu Chen*,
Zichen Liu*,
Chao Du†,
Tianyu Pang,
Qian Liu,
Arunesh Sinha†,
Pradeep Varakantham†,
Min Lin
International Conference on Learning Representations (ICLR), 2025
MHFAIA @ International Conference on Machine Learning (MHFAIA @ ICML), 2024
arXiv /
code
|
|
|
Unlocking Large Language Model's Planning Capabilities with Maximum Diversity Fine-tuning
Wenjun Li,
Changyu Chen,
Pradeep Varakantham
Findings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-Findings), 2025
arXiv
|
|
|
On Learning Informative Trajectory Embeddings for Imitation, Classification and
Regression
Zichang Ge*,
Changyu Chen*,
Arunesh Sinha,
Pradeep Varakantham
International Conference on Autonomous Agents and Multiagent Systems
(AAMAS), 2025
arXiv /
code
|
|
|
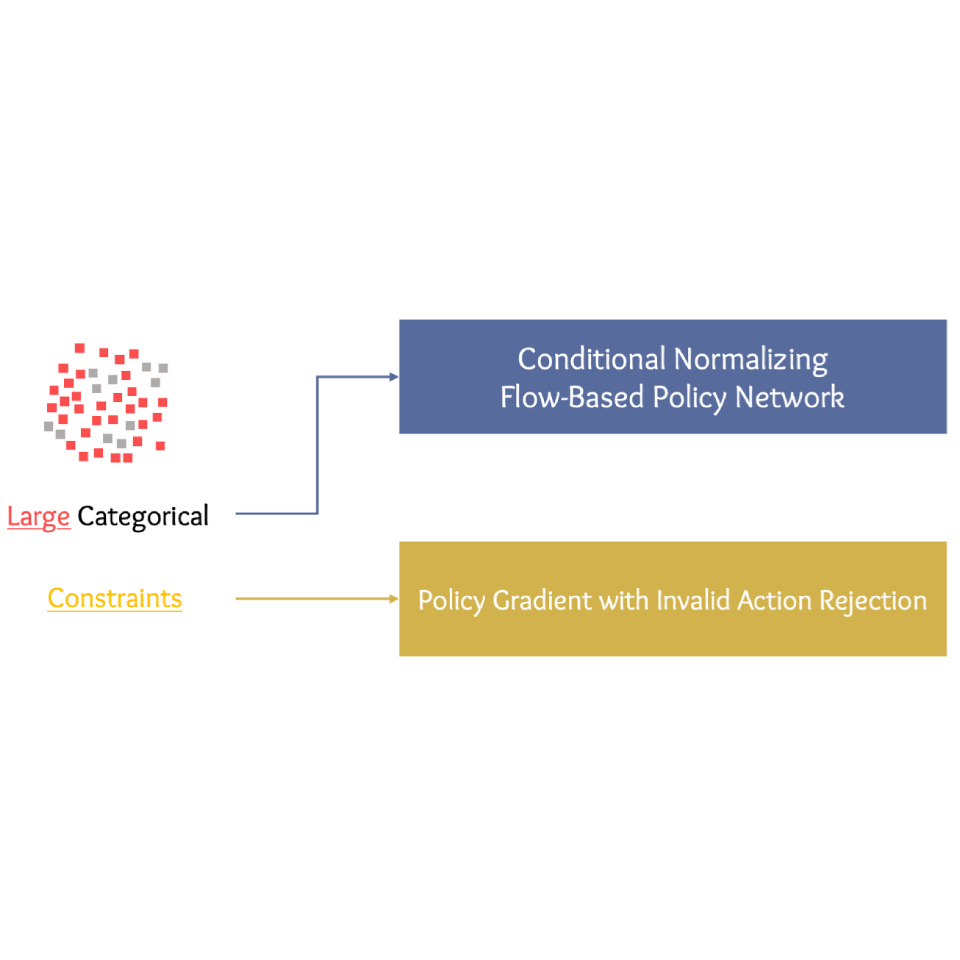
Generative Modelling of Stochastic Actions with Arbitrary Constraints in
Reinforcement
Learning
Changyu Chen,
Ramesha Karunasena,
Thanh Hong Nguyen,
Arunesh Sinha,
Pradeep Varakantham
Advances in Neural Information Processing Systems (NeurIPS), 2023
project page /
arXiv /
code
|
|
|
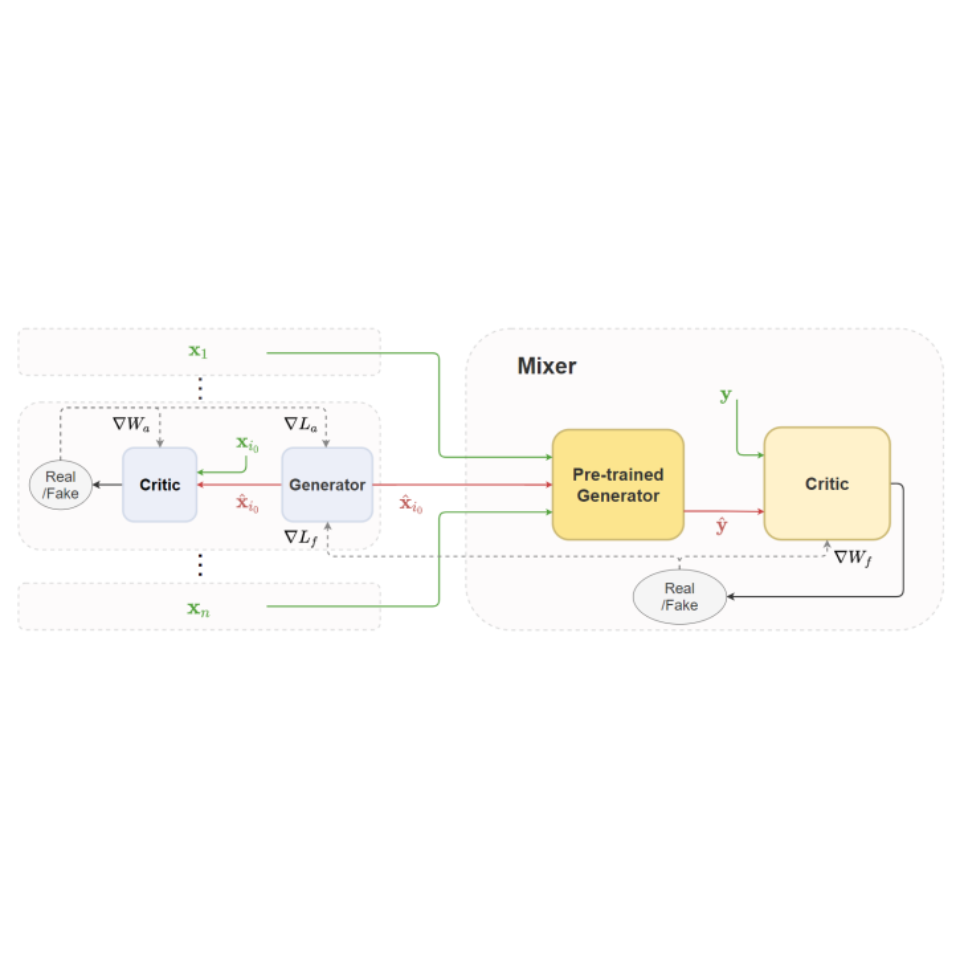
Multiscale Generative Models: Improving Performance of a Generative Model Using
Feedback
from Other Dependent Generative Models
Changyu Chen,
Avinandan Bose,
Shih-Fen Cheng,
Arunesh Sinha,
Annual AAAI Conference on Artificial Intelligence (AAAI), 2022
arXiv /
code
|
|
† denotes corresponding author
* denotes equal contribution
|
|